37× Over Budget: How I Solved an "Impossible" GitHub Rate Limit Problem
Two separate critical bug bounty payouts. Same root cause. Same blind spot I’d been shipping around for months.
That was the wake-up call. What followed was one of the more interesting constraint-satisfaction puzzles I’ve worked through, and the shape of the problem is general enough that I think it’s worth writing up.
The Blind Spot
I work on a service that continuously monitors our infrastructure for security issues including accidentally exposed secrets across our git surface. Credentials, API keys, internal config files. The kind of thing that, if found by the wrong person, becomes a very expensive afternoon.
The detection logic was solid. We process events on push, and the system had been running in production for years without major drama.
But twice, bounty hunters found something we missed. Both times, the pattern was identical: a developer accidentally committed a secret, realized their mistake, and force-pushed to rewrite history. On the surface the commit was gone, but it was trivially recoverable. Both bounty hunters found it the same way: open the repo’s Activity tab, filter by “Force push,” and the orphaned SHA is right there in the list.
Our pipeline never saw it, because by the time we polled the ref, it pointed somewhere new.
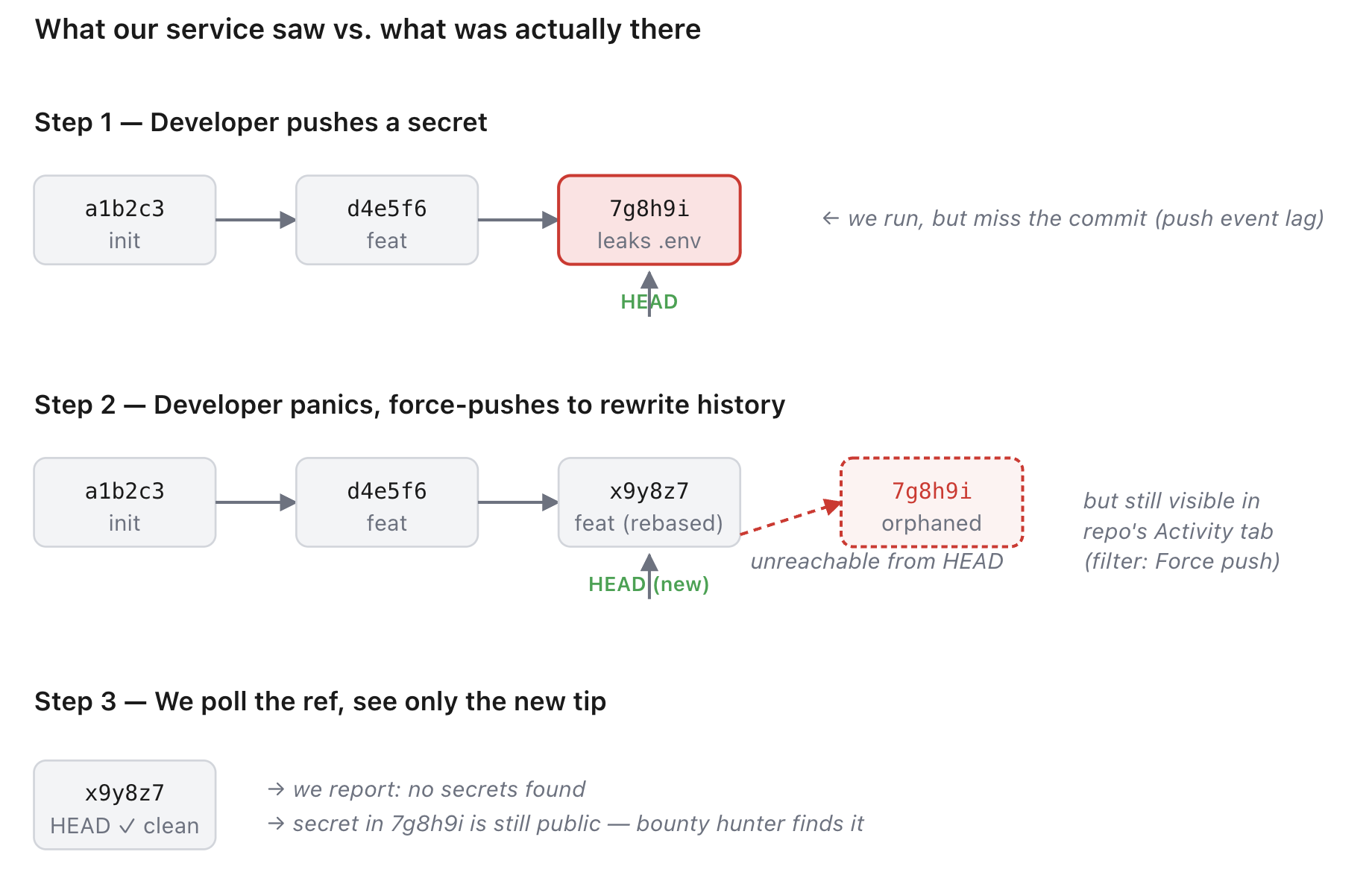
The fix sounded simple: pull before and head SHAs out of force-push events, compare them, and scan everything in between.
Then I started doing the math.
Solution 1: The GH Archive Approach (and Why I Killed It)
A teammate floated the idea of building it ourselves using GH Archive. We talked it through not as a finished design, more “what would this even look like if we went this way”:
- Persist every commit SHA we’d ever observed for each monitored repo (keyed by external repo ID, not name repos get renamed).
- On every poll, when a new
headis detected, look it up in the hash map. - If we’d seen the SHA before but it wasn’t currently the head, that’s the linked-list cycle case a force push had rewritten history, and we needed to process from the previous head forward to the rediscovered SHA.
It’s literally Floyd’s cycle detection applied to git refs. Clean, self-contained, doesn’t depend on GitHub’s API behaving a particular way.
It also had problems:
- Storage. Either a giant MySQL table holding every commit ID across everything we monitor, or BigQuery against GH Archive at roughly $160 per query. Neither was cheap.
- Edge cases. The “easy in competitive programming” version doesn’t survive contact with reality. What if a commit gets pushed and force-pushed between our polls? The bad SHA was never registered, so the cycle detection has nothing to detect. You’d need to walk the full diff between
beforeandheadregardless which means you’re already most of the way to a different solution. - Engineering effort. New database. New query patterns. New optimization work. New failure modes.
Then I noticed GitHub had quietly shipped exactly the endpoint I needed:
GET /repos/{owner}/{repo}/activity?activity_type=force_push&per_page=100
Then we call the .patch to get what changes were made in that commit
GET /repos/{owner}/{repo}/commits/{before_sha}
Accept: application/vnd.github.patch
…the whole problem collapses into two API calls per force-push event. No new database. No cycle detection. Just use the platform.
I dropped Solution 1 and built against the activity endpoint.
The Math That Breaks Everything
We monitor >46,000 targets. To stay within our detection-latency budget, we run a full pass four times per hour. Plus ad-hoc work triggered by external events.
That’s 180,000+ API calls per hour, before the new force-push detection logic adds anything.
GitHub’s rate limits, for reference:
- 60 rph per IP for unauthenticated requests
- 5,000 rph per token for PAT (personal access tokens)
- 15,000 rph per token for IAT (installation access tokens - what GitHub Apps get)
At 180,000+ calls, we were roughly 37× over what our standard PAT allows. Even using GitHub Apps (which we started doing for some flows prior to this upgrade, giving us the higher 15k/hour bucket per org), there was a massive budget gap. We have multiple orgs, each with its own installation, but the baseline load was already devouring our capacity.
37× over what a single PAT token allows. Real budget gap even across all our orgs.
What Happened When I Shipped It Anyway
The force-push detection was something that was needed urgently and I had tested it with a few targets and it was able to work so I shipped it. Within a few hours we got a lot of force pushed commits and started scanning but soon after they dropped in number.
What actually happened was worse. The new logic tipped us hard over the rate limit, jobs started failing on every retry, and Sidekiq quietly moved them into the dead queue. The worker scheduler was polling-based with the interval stored in the database, each job re-queues itself after completion by reading its repeat interval from the DB. When jobs went to dead, they didn’t re-queue. They didn’t re-anything. They just sat there.
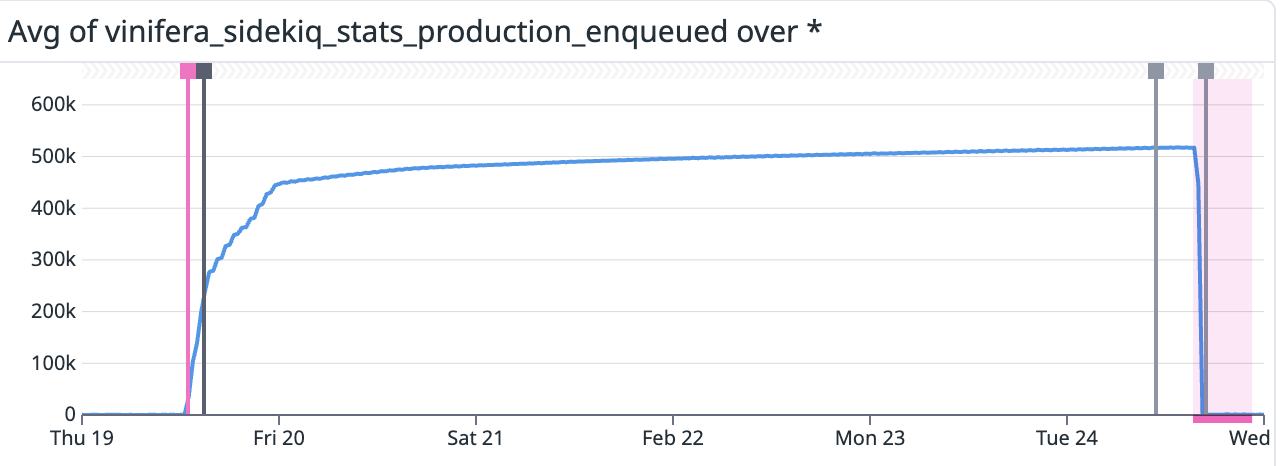
We had Datadog metrics that clearly reflected the failure. We didn’t have PagerDuty wired up for this specific failure mode. So jobs kept dying silently until my manager spot-checked the dashboard later and noticed entire worker classes had gone quiet.
Two lessons from that:
- Never scale to 100% - usually whatever i had shipped changed the entire flows, so to roll this new feature out with something as simple as trigger if rand(0,100) < 5 : was not done
- PD coverage needs to follow new failure modes, not just new services. The service was paged. The specific way it could now fail was not.
After we recovered, we were still hitting rate limits on the original workload — about 660k errors/day, ~11% of all requests. The retries were eating their own budget.
First Instinct: Token Pooling (and Why I Almost Did It Wrong)
Across our internal tenants, the load was extremely uneven. A handful of large tenants were the source of nearly all the rate-limit errors. Several tenants were sitting on 14,000+ unused requests per hour, every hour.
Obvious fix: pool the IAT tokens. When tenant A is running low, transparently use tenant B’s token. Implement it deep in the HTTP client so the rest of the codebase doesn’t even know.
My manager pushed back, and after thinking about it he was right.
Silently using one tenant’s API credentials to do work for another even when we control all the tenants, is bad practice. It muddles the audit trail. It creates unexpected attribution. It sets a precedent that credentials are interchangeable. Even in a fully internal setting, “quiet borrowing” is the kind of thing that creates a confusing debugging session six months later when someone is trying to figure out which tenant’s quota actually got consumed during a spike.
We discussed alternatives separate apps, multiple IATs, ETag-based caching to avoid re-fetching unchanged data. ETags died fast: every IAT gets a different ETag for the same resource, so caching across tokens doesn’t help, and we still scan four times per hour regardless.
The right shape of the original idea was opt-in pooling:
- Tenants explicitly join the pool by setting a feature flag.
- Pool members can borrow headroom from each other when running low.
- Borrowing is logged and attributable.
We framed it commercially too: tenants who opt into the pool get a discount, since they’re contributing unused capacity back. That made the tradeoff explicit instead of hiding it in infrastructure.
I flagged our heaviest tenants and a few near-zero-usage tenants into the pool, shipped it, and watched the rate-limit errors collapse.
For about an hour. Then they started climbing again.
The Constraint I Didn’t Expect
GitHub has a long-standing quirk: org B’s token can’t read org A’s repos when org A has IP whitelisting enabled even for repos that would otherwise be public to that token.
This matters because once you’re pooling tokens, you might use org B’s token to scan something in org A’s namespace. If org A has IP restrictions configured on its GitHub App, that request comes back as a 403 Forbidden and it looks like a permissions bug, not a pooling architecture issue.
Our errors didn’t go away. They shape-shifted. Rate-limit errors dropped. 403s climbed. We hit ~1-2% error rate and trending up.
The pooled tokens weren’t universally interchangeable. They were only safe for org-agnostic work.
So I split the routing into two lanes:
- Org-specific reads - anything that touches a particular org’s repos, always use that org’s own token. No borrowing.
- Org-agnostic work - user-account lookups, public-repo metadata checks, anything not tied to a specific org’s namespace, can fall back to the pool.
I added an is_this_org parameter to the token-resolution path. When parsing a slug <owner>/<repo-name>, we check if <owner> matches any of our tenants. If yes, is_this_org=true and pooling is disabled for this request — that tenant’s own token gets used regardless of remaining budget.
This is a meaningful architectural split. The pooling logic has to be aware of what kind of request it’s handling, and the routing has to be explicit, not implicit.
The Edge Cases That Mattered
Three details I got wrong on the first pass and had to fix:
Hard floor on lending. Letting a tenant lend out requests until it hit zero would cause thrashing: a tenant would burn its budget helping others, then immediately need to borrow back to do its own work but that would fail because of the 403 quirk we discussed. I anticipated this before shipping and built in a hard floor of 100 requests that a tenant will never share below. Small enough not to meaningfully shrink the pool, large enough to guarantee each tenant can finish its own urgent work.
Borrowing threshold. When should a tenant start borrowing instead of using its own budget? I started at 5,000 remaining requests, then bumped to 9,000 incrementally after watching how the load actually distributed. Earlier handoff means more headroom for in-flight org-specific work that can’t fall back to the pool. The 9k isn’t a magic number and it can be tuned further, it came from empirical observation, not first principles.
The deadlock case. This one was subtle. Tenant A is below threshold, falls back to the pool, picks tenant B (highest remaining RL). But B is also below threshold, so its token-creation path triggers its fallback, which might pick A or some third under-budget tenant. In the worst case you’ve got a cycle, or at minimum a chain of fallbacks resolving at runtime under contention.
Fix: add a boolean to the token-creation call - is_fallback. When the pooling path calls back into token creation for a different tenant, it sets is_fallback=true. The recipient sees the flag, skips its own fallback path entirely, and either uses its own IAT or throws an error. One level of indirection, max. This eliminates the cycle and makes the system bounded and easy to reason about.
The Results
After shipping the full pooling system with the routing split and the three fixes above:
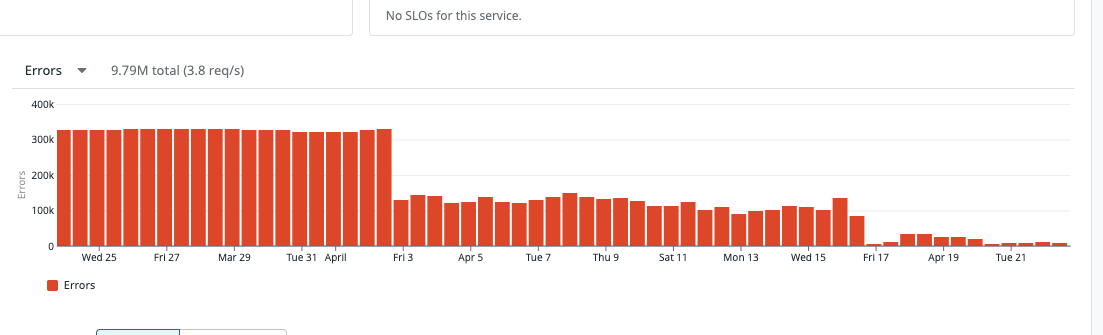
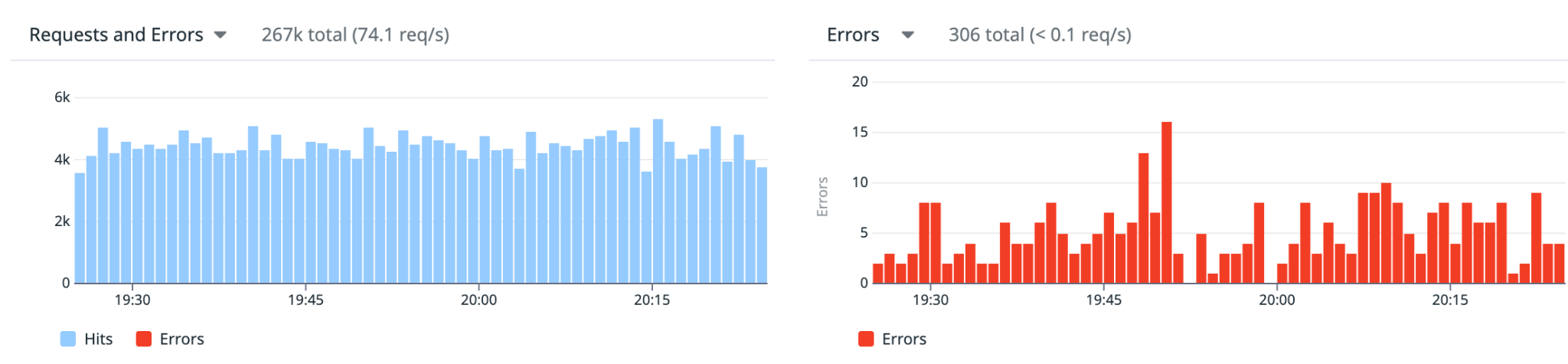
- Rate-limit errors dropped from ~660k/day (~11%) to under 15k/day (~0.2%)
- Sustained scan throughput went from 64 to 72 RPS
- Slack error channel went from a wall of
Octokit::TooManyRequeststo actual signal again - Visibility on the force-pushed commits across tenants.
The error-rate improvement is the more important number. Most of those 660k daily errors weren’t fatal, the system retried - but each retry consumed another request against the rate-limit budget, creating a feedback loop where errors begat more errors. Fixing the pooling broke the cycle.
The throughput gain is a second-order effect of the same fix: fewer retries means more of the budget goes to actual work instead of redoing failed work.
It’s not perfect. We still see errors. But we dropped them by ~98% and got our visibility back.
The Lesson I Keep Coming Back To
Most constraint problems mix two kinds of constraints together: ones that feel fixed but aren’t, and ones that genuinely are.
The rate limit per org felt fixed. GitHub sets it, you live with it. But the unit that actually matters is tokens, not orgs and tokens can be pooled, and the effective budget is much larger than it first looks. That constraint was negotiable.
The IP whitelisting behavior was genuinely fixed. GitHub’s decision about which token can access which org’s resources is not something you argue with at the application layer. The right move was to route around it, not fight it.
Sorting which constraints are load-bearing and which are just load-bearing-seeming is most of the actual work. Everything else is implementation detail.
If you’ve run into similar token-pooling or rate-limit problems with GitHub at scale, I’d be curious how you approached it.